

Cloudflare says an infinite outage that affected better than a dozen of its data amenities and a complete bunch of foremost on-line platforms and suppliers presently was introduced on by a change that should have elevated group resilience.
“In the mean time, June 21, 2022, Cloudflare suffered an outage that affected website guests in 19 of our data amenities,” Cloudflare said after investigating the incident.
“Sadly, these 19 areas cope with an enormous proportion of our worldwide website guests. This outage was introduced on by a change that was part of a long-running endeavor to increase resilience in our busiest areas.”
In response to user reportsthe whole itemizing of affected web pages and suppliers accommodates, nonetheless it isn’t restricted to, Amazon, Twitch, Amazon Web Corporations, Steam, Coinbase, Telegram, Discord, DoorDash, Gitlab, and further.
Outage affected Cloudflare’s busiest areas
The company began investigating this incident at roughly 06:34 AM UTC after research of connectivity to Cloudflare’s group being disrupted began coming in from prospects and prospects worldwide.
“Prospects attempting to reach Cloudflare web sites in impacted areas will observe 500 errors. The incident impacts all data airplane suppliers in our group,” Cloudflare said.
Whereas there are not any particulars regarding what induced the outage inside the incident report revealed on Cloudflare’s system standing website, the company shared additional data on the June 21 outage on the official weblog.
“This outage was introduced on by a change that was part of a long-running endeavor to increase resilience in our busiest areas,” the Cloudflare group added.
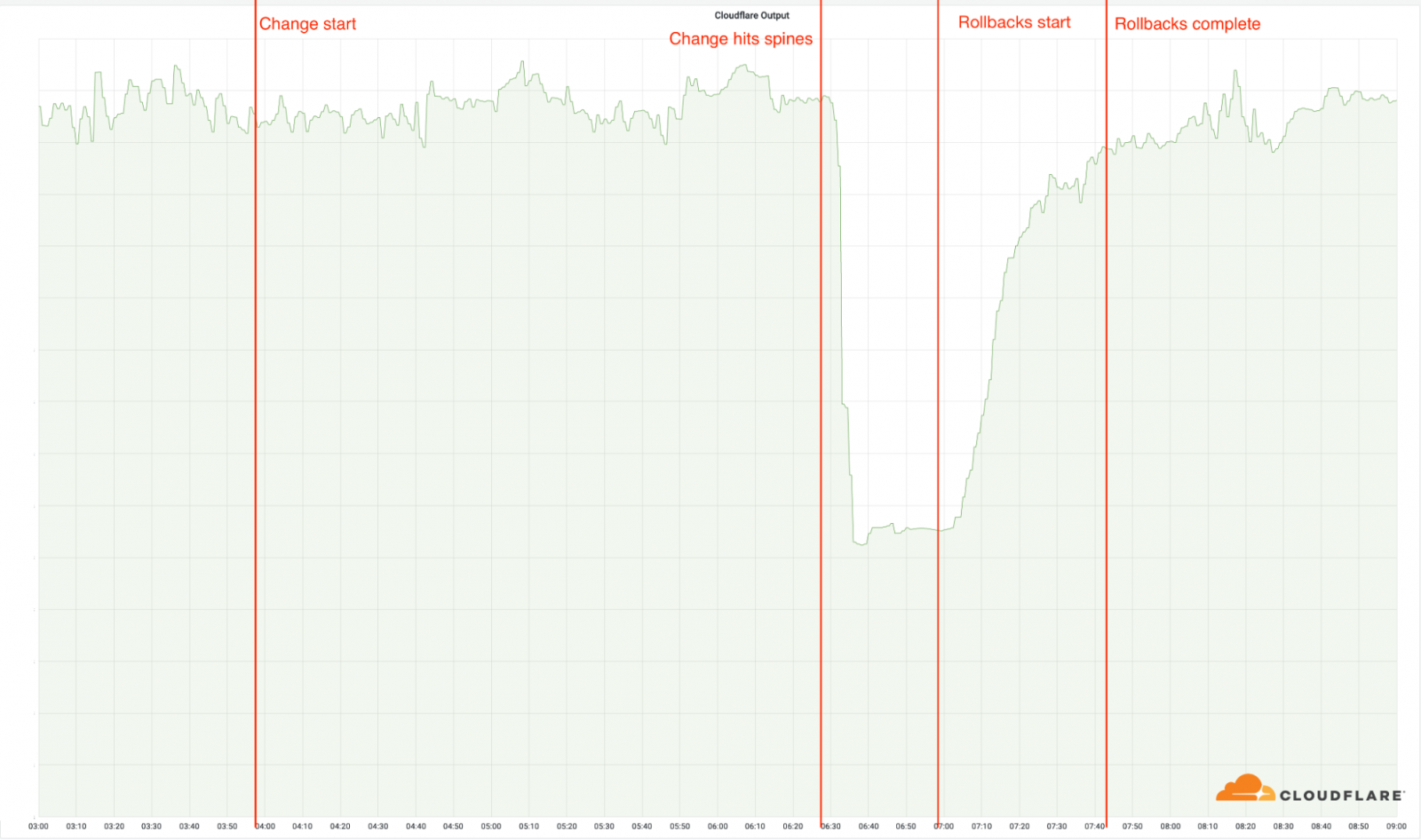
“A change to the group configuration in these areas induced an outage which started at 06:27 UTC. At 06:58 UTC the first data coronary heart was launched once more on-line and by 07:42 UTC all data amenities had been on-line and dealing appropriately.
“Relying in your location on this planet you will have been unable to entry web pages and suppliers that rely on Cloudflare. In several areas, Cloudflare continued to perform often.”
Although the affected areas characterize solely 4% of Cloudflare’s full group, their outage impacted roughly 50% of all HTTP requests handled by Cloudflare globally.
The change that led to presently’s outage was half of a much bigger endeavor that may convert data amenities in Cloudlfare’s busiest areas to additional resilient and versatile construction, recognized internally as Multi-Colo PoP (MCP).
The itemizing of affected data amenities in presently’s incident accommodates Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, London, Los Angeles, Madrid, Manchester, Miami, Milan, Mumbai, Newark, Osaka, São Paulo, San Jose, Singapore, Sydney, and Tokyo.
Outage timeline:
3:56 UTC: We deploy the change to our first location. None of our areas are impacted by the change, as these are using our older construction.
06:17: The change is deployed to our busiest areas, nevertheless not the areas with the MCP construction.
06:27: The rollout reached the MCP-enabled areas, and the change is deployed to our spines. That’s when the incident startedas this shortly took these 19 areas offline.
06:32: Internal Cloudflare incident declared.
06:51: First change made on a router to verify the premise set off.
06:58: Root set off found and understood. Work begins to revert the problematic change.
07:42: The ultimate of the reverts has been completed. This was delayed as group engineers walked over each other’s changes, reverting the sooner reverts, inflicting the problem to re-appear sporadically.